Mounted at /content/drive![]()
https://www.kaggle.com/datasets/arjuntejaswi/plant-village

431nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1, stride=1) 256 - 3 + 2 + 1 = 256
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,padding = 0, stride=2), (256-2)/2 + 1 = 128
nn.Conv2d(32, out_channels=64, kernel_size=3, padding=1, stride = 1) # 128
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2), (128-2)/2 + 1 = 64
class myCNN(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels, out_channels=32, kernel_size=3, padding=1, stride=1), # 256
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,padding = 0, stride=2), #(256-2)/2 + 1 = 128
nn.Conv2d(32, out_channels=64, kernel_size=3, padding=1, stride=1), # 128
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2), #(128-2)/2 + 1 = 64
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=64*64*64, out_features=128),
nn.ReLU(),
nn.Linear(in_features=128, out_features=32),
nn.ReLU(),
nn.Linear(in_features=32, out_features=3),
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) <ipython-input-41-c3b9c4548463> in <cell line: 0>() 1 from torchsummary import summary ----> 2 summary(myCNN(3), (3, 256, 256)) /usr/local/lib/python3.11/dist-packages/torchsummary/torchsummary.py in summary(model, input_size, batch_size, device) 70 # make a forward pass 71 # print(x.shape) ---> 72 model(*x) 73 74 # remove these hooks /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs) 1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc] 1738 else: -> 1739 return self._call_impl(*args, **kwargs) 1740 1741 # torchrec tests the code consistency with the following code /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1748 or _global_backward_pre_hooks or _global_backward_hooks 1749 or _global_forward_hooks or _global_forward_pre_hooks): -> 1750 return forward_call(*args, **kwargs) 1751 1752 result = None <ipython-input-39-c5da7a43d213> in forward(self, x) 24 25 def forward(self, x): ---> 26 x = self.features(x) 27 x = self.classifier(x) 28 return x /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs) 1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc] 1738 else: -> 1739 return self._call_impl(*args, **kwargs) 1740 1741 # torchrec tests the code consistency with the following code /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1748 or _global_backward_pre_hooks or _global_backward_hooks 1749 or _global_forward_hooks or _global_forward_pre_hooks): -> 1750 return forward_call(*args, **kwargs) 1751 1752 result = None /usr/local/lib/python3.11/dist-packages/torch/nn/modules/container.py in forward(self, input) 248 def forward(self, input): 249 for module in self: --> 250 input = module(input) 251 return input 252 /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _wrapped_call_impl(self, *args, **kwargs) 1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc] 1738 else: -> 1739 return self._call_impl(*args, **kwargs) 1740 1741 # torchrec tests the code consistency with the following code /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in _call_impl(self, *args, **kwargs) 1843 1844 try: -> 1845 return inner() 1846 except Exception: 1847 # run always called hooks if they have not already been run /usr/local/lib/python3.11/dist-packages/torch/nn/modules/module.py in inner() 1791 args = bw_hook.setup_input_hook(args) 1792 -> 1793 result = forward_call(*args, **kwargs) 1794 if _global_forward_hooks or self._forward_hooks: 1795 for hook_id, hook in ( /usr/local/lib/python3.11/dist-packages/torch/nn/modules/conv.py in forward(self, input) 552 553 def forward(self, input: Tensor) -> Tensor: --> 554 return self._conv_forward(input, self.weight, self.bias) 555 556 /usr/local/lib/python3.11/dist-packages/torch/nn/modules/conv.py in _conv_forward(self, input, weight, bias) 547 self.groups, 548 ) --> 549 return F.conv2d( 550 input, weight, bias, self.stride, self.padding, self.dilation, self.groups 551 ) RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
#@title mini-batch SGD
torch.manual_seed(42)
# define the model
model = myCNN(3)
model.to(device)
optimizer = optim.SGD(model.parameters(), lr = 0.01)
EPOCHS = 30
model.train()
for epoch in range(EPOCHS):
loss_per_epoch = 0
for features, labels in train_loader:
features = features.to(device)
labels = labels.to(device)
# forward pass
y_pred = model.forward(features)
# loss computation
loss_func = nn.CrossEntropyLoss()
loss = loss_func(y_pred, labels)
#make gradients zero
optimizer.zero_grad()
# backward pass
loss.backward()
#weight updates
optimizer.step()
loss_per_epoch += loss
print("loss per epoch =", loss_per_epoch)
loss per epoch = tensor(50.2412, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(48.3563, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(47.0469, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(43.2188, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(38.6456, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(30.8681, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(27.7246, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(24.7008, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(22.7491, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(19.2236, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(18.2339, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(15.0300, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(13.8764, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(13.5498, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(12.2096, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(12.9050, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(10.6831, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(10.3771, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(9.8746, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(9.3130, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(8.9060, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(8.0116, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(9.3495, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(6.4980, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(6.8276, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(6.5630, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(5.1249, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(5.5866, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(4.3341, device='cuda:0', grad_fn=<AddBackward0>)
loss per epoch = tensor(3.4490, device='cuda:0', grad_fn=<AddBackward0>)myCNN(
(features): Sequential(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=262144, out_features=128, bias=True)
(2): ReLU()
(3): Linear(in_features=128, out_features=32, bias=True)
(4): ReLU()
(5): Linear(in_features=32, out_features=3, bias=True)
)
)tensor(0.0296, device='cuda:0')torch.return_types.max(
values=tensor([ 4.1801, 7.2777, 2.9228, 6.6978, 6.2466, 6.4976, 10.6728, 13.8182,
4.3439, 6.2930, 16.3630, 7.0854, 2.2427, 7.9813, 10.0596],
device='cuda:0'),
indices=tensor([1, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0], device='cuda:0'))# evaluation on test data
total = 0
correct = 0
with torch.no_grad():
for batch_features, batch_labels in test_loader:
# move data to gpu
batch_features, batch_labels = batch_features.to(device), batch_labels.to(device)
outputs = model(batch_features)
_, predicted = torch.max(outputs, 1)
total = total + batch_labels.shape[0]
correct = correct + (predicted == batch_labels).sum().item()
print(correct/total)0.974477958236659tensor([[ -2.9959, 4.1801, -2.4294],
[ 7.2777, 1.8925, -7.3953],
[ -3.6748, 2.9228, -0.5214],
[ -2.4880, 6.6978, -5.6649],
[ 6.2466, 2.2855, -7.0979],
[ 3.2276, 6.4976, -9.9211],
[ 10.6728, 3.8097, -12.0863],
[ 13.8182, 3.0021, -13.6187],
[ -2.4990, 4.3439, -2.9725],
[ 6.2930, 1.8244, -6.5667],
[ 16.3630, 4.1882, -16.8436],
[ -4.5475, 7.0854, -4.6040],
[ 1.2956, 2.2427, -3.3800],
[ -3.3519, 7.9813, -6.5117],
[ 10.0596, 4.4465, -12.3882]], device='cuda:0')# prompt: plot the confusion matrix for this
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import seaborn as sns
# Assuming 'test_loader', 'model', and 'device' are defined as in your previous code
y_true = []
y_pred = []
with torch.no_grad():
for batch_features, batch_labels in train_loader:
batch_features, batch_labels = batch_features.to(device), batch_labels.to(device)
outputs = model(batch_features)
_, predicted = torch.max(outputs, 1)
y_true.extend(batch_labels.cpu().numpy())
y_pred.extend(predicted.cpu().numpy())
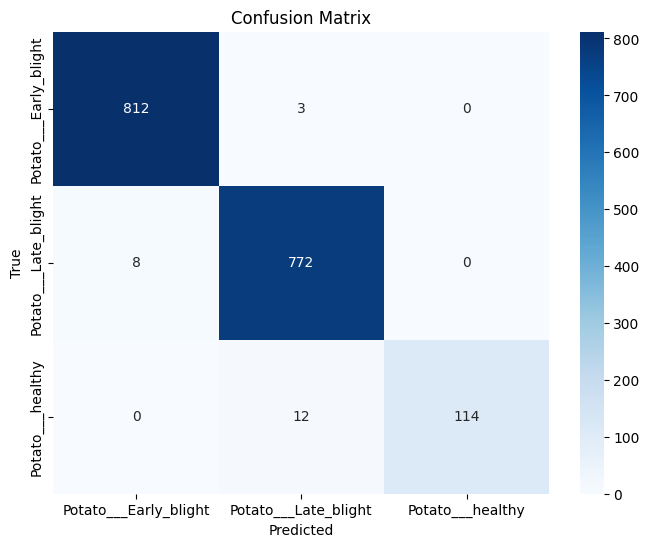
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=full_dataset.classes, yticklabels=full_dataset.classes)
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()