For an input x_i, we generate a label y_i by using a fixed \mathbf{w} and a random normal variable ϵ ∼ N(0, 0.1^2) in the following fashion:
y_i = \mathbf{w}^{T}x_i + ϵ
We generate a dataset with 100 samples, each having 50 features. We sample the first 25 features from a gaussian - meaning they are uncorrelated, and add 25 more features that are linearly correlated with the current ones.
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import make_regressionn =100d =25# Dataset with 25 uncorrelated featuresnp.random.seed(7)# X = np.random.normal(size=(n, d))X, y = make_regression(n_samples=n, n_features=d, noise=1, random_state=2)# Add 25 correlated features:for j inrange(d): a = np.random.normal(size=d+j) new_feature = X@np.vectorize(lambda i: int(i)*np.random.randint(-2, high=2))(a>1) X = np.c_[X, new_feature]X = X.Tplt.matshow(np.corrcoef(X))cb = plt.colorbar()cb.ax.tick_params()plt.title('Correlation Matrix');
We then make a sparse \mathbf{w} vector with 10/50 features non-zero. We use this to generate \mathbf{y} using the model discussed above.
d *=2np.random.seed(69)r_d =10# Make sparse w with 10 featuresw = np.zeros(d)relevant = np.random.randint(0, high=d-1, size=r_d)# Assign some weight to these features onlyw[relevant] = np.random.normal(scale=2, size=r_d)# Create some noise, and find predictorsy = w.T @ X + np.random.normal(scale=0.01, size=n)
Maximum-Likelihood Estimator for finding w
The closed form solution for the ML estimator to solve the linear regression problem with the given probabilistic model is the following:
\hat{\mathbf{w}}_{ML} = (XX^T)^†Xy
w_hat_ml = np.linalg.pinv(X @ X.T) @ X @ y
Goodness of ML Estimator
To quantify “goodness” of our estimator, we look at the Mean Squared Error.
Mean Squared Error: Let \mathbf{\hat{w}} be an estimator of an unknown parameter \mathbf{w}. Then we define
where \text{tr}(\text{Var}(\mathbf{\hat{w}})) is the trace of the covariance matrix, and \text{Bias}(\mathbf{\hat{w}}) = \mathbb{E}[\mathbf{\hat{w}}] - \mathbf{w}
is the bias, i.e, the expected difference between the estimator \mathbf{\hat{w}} and true value \mathbf{w}.
Applying Bias-Variance decomposition on ML Estimator of w
We use the below well-known formula relating the covariance matrix \text{Var}(X) to the first and second moments: \mathbb{E}[X^2] = (\mathbb{E}[X])^2 + \text{Var}(X)
We see that the goodness of the ML estimate depends on the variance of error σ^2 and \text{tr}((XX^T)^{-1}). We would like to reduce this quantity.
The variance of error is inherent to the experimental setup, and reduction of this quantity therefore depends on qualitative improvements of instruments/peripherals used to collect data. So we cannot hope to reduce this quantity from a mathematical perspective.
The trace depends on (XX^T)^{-1}, which denotes the inverse covariance matrix of the data X. The covariance matrix captures how the features are related with each other, and it seems that this relation affects the goodness of our estimator. We may try to tweak this value to reduce the trace value, thereby increasing the goodness of our ML estimator.
Reducing the Trace value
The trace of a matrix X can also be represented as the sum of the eigenvalues of X.
Let \mathbf{λ} denote the set of eigenvalues of XX^T. Then \{ \frac{1}{λ_i} \; ∀ \; i \; \epsilon \; \{1, 2, .., n\} \} is the set of eigenvalues of (XX^T)^{-1} and its trace thus is the following:
Note that both \text{(A)} and \text{(B)} are positive quantities, hence the difference can either be positive or negative; The difference depends on the parameter \lambda.
The existence theorem asserts that there exists some non-zeroλ such that the MSE of \hat{\mathbf{w}}_{\lambda - ML} is lower than that of \hat{\mathbf{w}}_{ML}, i.e we get \text{(A)} > \text{(B)}.
Ridge Regression
The method of estimating w while reducing the effect inter-correlated variables have on the ML estimator for linear regression is called Ridge Regression.
The objective of the ridge regression problem is given as follows:
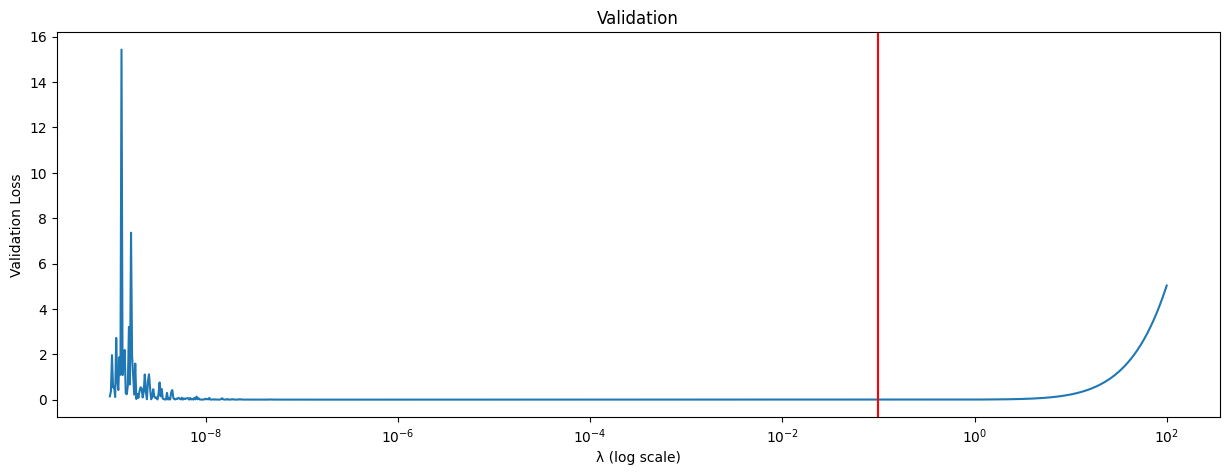
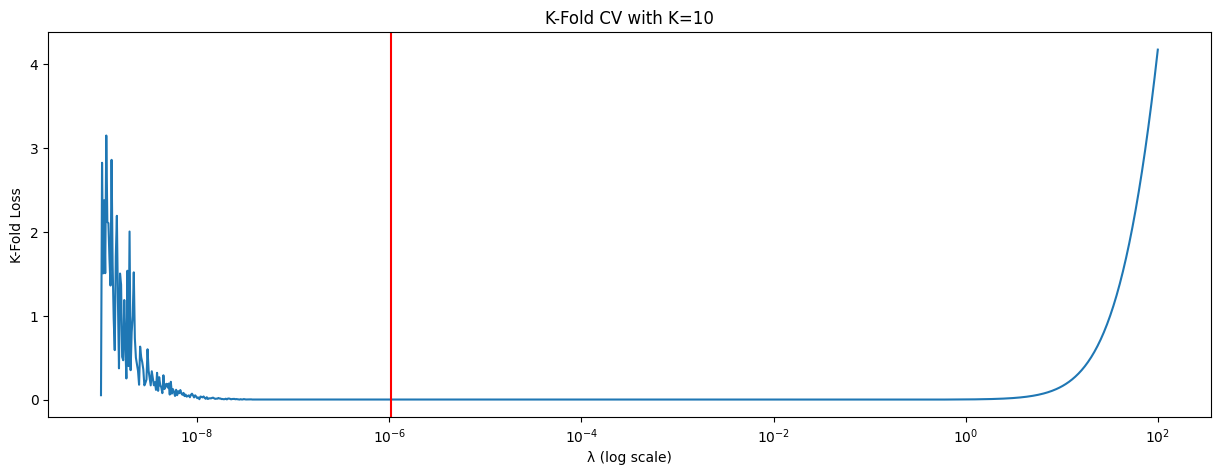
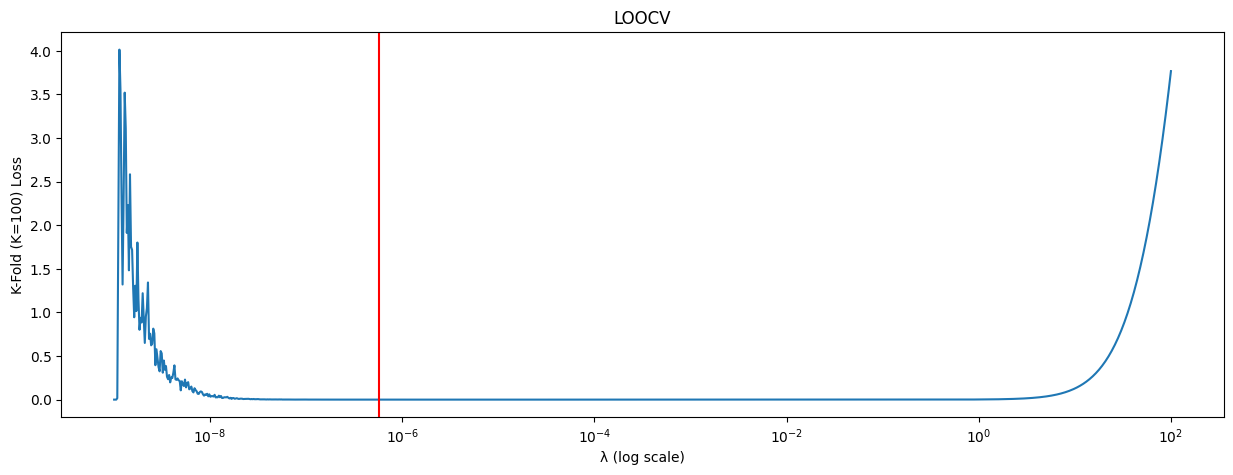
The λ term is called the regularizer, and is a hyperparameter, which can be chosen through the cross-validation technique, described at the end of this notebook.
Closed-Form Solution for Ridge Estimator
It is the same as the aforementioned \hat{\mathbf{w}}_{\lambda - ML}:
It’s good to know that the inverse of (XX^T + λI) always exists since: 1. (XX^T) is positive semi-definite 2. \lambda > 0
Hence (XX^T + λI) is a positive definite matrix (i.e. all eigenvalues are strictly positive - full rank) - indicating its inverse exists.
l =10w_hat_ridge = np.linalg.inv(X @ X.T + l * np.eye(d)) @ X @ y
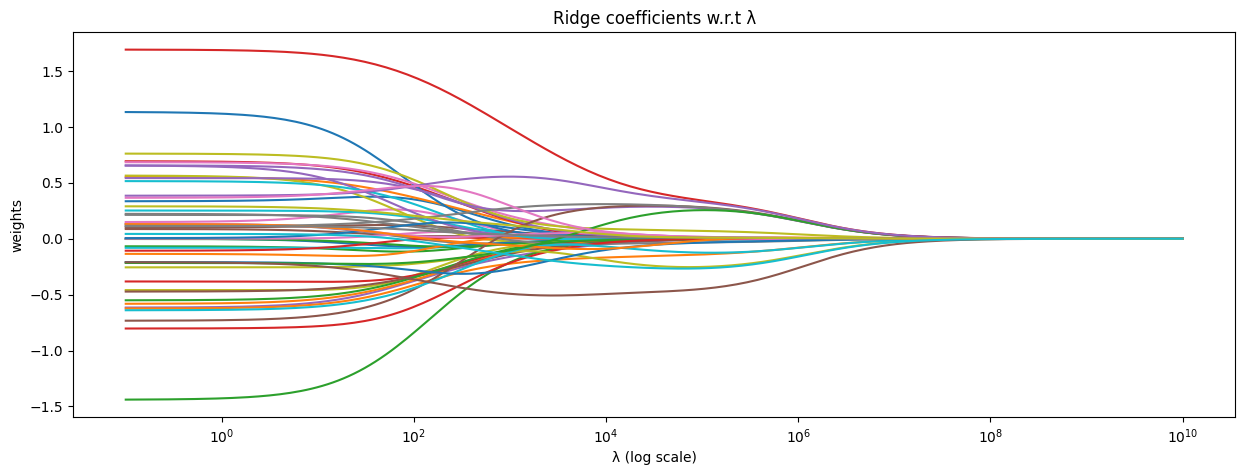
Comparison of Ridge and Linear Regression Solutions
The \lambda ||w||^2_2 term in the objective function for Ridge regression penalizes the score for w’s with greater length. This thus pushes the ridge estimator closer to the origin, resulting in smaller values in its components.
We show the effect of varying \lambda over the coefficients of ridge
lambdas = np.logspace(-1, 10 , 200)from sklearn.linear_model import Ridgecoefs = []for l in lambdas: w_hat_ridge = np.linalg.pinv(X @ X.T + l * np.eye(d)) @ X @ y coefs.append(w_hat_ridge)fig, ax = plt.subplots(figsize=(15, 5))ax.plot(lambdas, coefs)ax.set_xscale("log")# ax.set_xlim(ax.get_xlim()[::-1]) # reverse axisplt.xlabel("λ (log scale)")plt.ylabel("weights")plt.title("Ridge coefficients w.r.t λ")plt.axis("tight")plt.show()
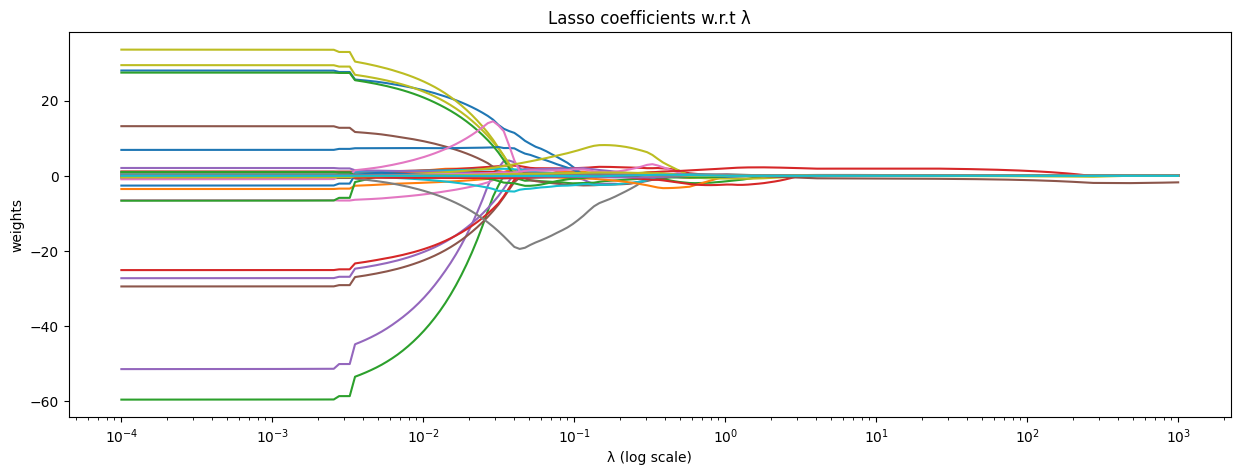
Lasso Regression
The objective for the lasso regression problem is as follows:
The only difference between Lasso and Ridge is that Lasso uses the L1 norm (manhattan distance), in contrast to the L2 norm (euclidean distance) used by Ridge regression. This difference adds sparsity to the Lasso estimator; i.e, some feature co-efficients are pushed to 0; these features do not play a role in the final prediction.
In this context, Lasso can be said to perform feature-selection. Lasso also acts as a regularizer, in terms of constraining the length of the estimator.
Solution for Lasso Regression
There exists no closed form solution for Lasso, due to the constraint boundaries having points which are not differentiable.
Hence we may use the method of gradient descent, with the help of subgradients to find the Lasso estimator.
In this notebook we use scikit-learn’s implementation of Lasso to demonstrate the effect of the Lasso objective on our estimator.