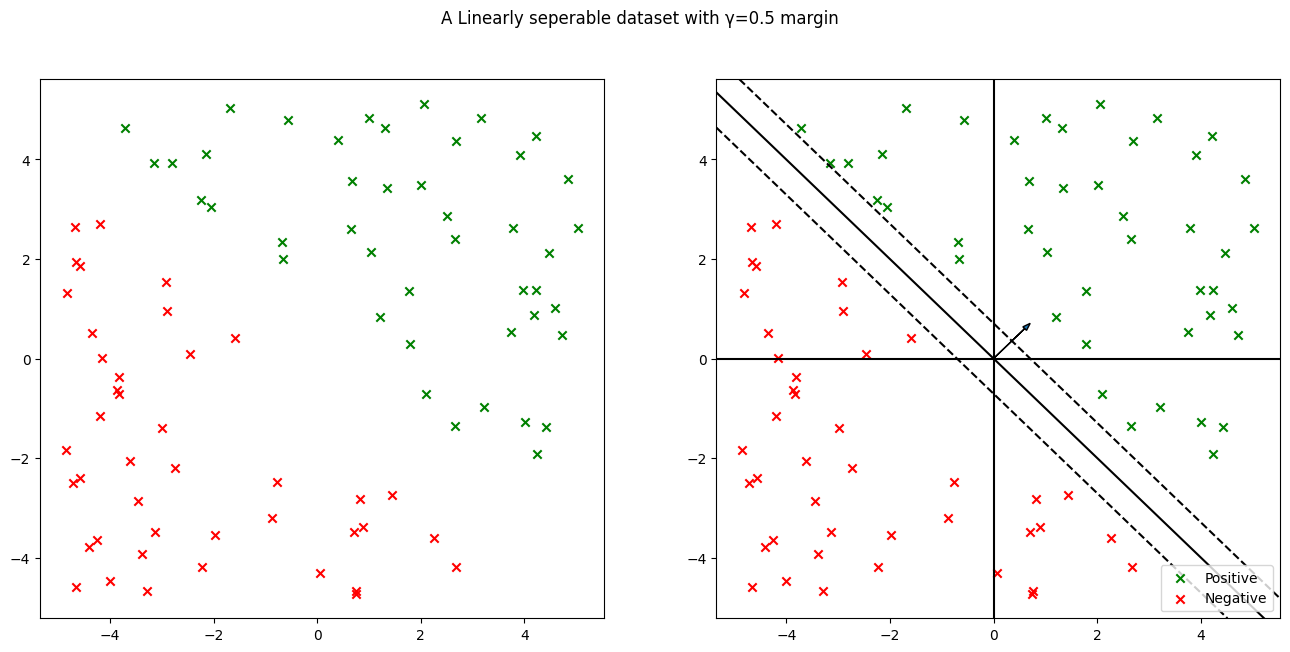
Perceptron converges to \mathbf{w} =\begin{pmatrix}7.06\\10.34\end{pmatrix} after 9 updates.
Logistic Regression
We consider our prediction probabilty to be proportional to the distance of a point from the decision boundary. With this formulation, we use MLE to learn the best decision boundary for a given dataset.
We perform gradient descent (till convergence) as follows:
\mathbf{w}^{t+1} = \mathbf{w}^t - \eta \nabla \log L(\mathbf{w}^t)
w = np.array([0, 0])step =0.001def grad(w): y_proba = np.array([sigmoid(w, x) for x in X])return X.T@(y_proba-y)def error(w): l =0for i inrange(n): l += y[i]*np.log(sigmoid(w, X[i])) + (1-y[i])*np.log(1-sigmoid(w, X[i]))return-lw_next = w - grad(w) * stepn_iter =0results =r"Iteration Number $i$ | $\mathbf{w}$ | Error"+"\n--|--|--\n"while np.linalg.norm(w-w_next)>0.001and n_iter<41:ifnot n_iter%10or n_iter <=3: results +=str(n_iter)+r" | $$\begin{pmatrix}{"+str(round(w[0], 2)) +",\quad}{"+str(round(w[0], 2)) +r"}\end{pmatrix}$$ | "+f"{error(w):.2f}\n" w = w_next y_proba = np.array([sigmoid(w, x) for x in X]) grad_step = grad(w_next) * step w_next = w_next - grad_step n_iter+=1Markdown(results)
Iteration Number i
\mathbf{w}
Error
0
\begin{pmatrix}{0,\quad}{0}\end{pmatrix}
59.61
1
\begin{pmatrix}{0.09,\quad}{0.09}\end{pmatrix}
44.56
2
\begin{pmatrix}{0.16,\quad}{0.16}\end{pmatrix}
35.93
3
\begin{pmatrix}{0.21,\quad}{0.21}\end{pmatrix}
30.52
10
\begin{pmatrix}{0.42,\quad}{0.42}\end{pmatrix}
17.04
20
\begin{pmatrix}{0.57,\quad}{0.57}\end{pmatrix}
11.83
30
\begin{pmatrix}{0.67,\quad}{0.67}\end{pmatrix}
9.49
40
\begin{pmatrix}{0.74,\quad}{0.74}\end{pmatrix}
8.09
It’s worth noting that Logistic Regression can exhibit severe over-fitting on datasets that are linearly seperable. This happens since \mathbf{w} can be made arbitrarily large along this direction to minimize error. This phenomenon can be observed above, since the dataset in question is linearly seperable.
perceptron_w = np.array([7.06, 10.34])error(perceptron_w/3)# Scaling along this direction also yields -inf error
1.3071990315434519
One can get away with this singularity by introducing a regularization term (quantity that grows proportional to ||\mathbf{w}||) into the error function.
We illustrate this in our example again, using the following modified loss and gradient functions: