Nuanced situations end up providing complicated situations. One way of handling this is to view it as a mixture of simpler distributions - where the methodology of mixing is governed by the introduction of latent variables.
The problem can be then modelled into a Maximum Likelihood Estimation problem; but obtaining the parameters that best fit the data is not a straightforward task (no closed form solutions) (singularity problems)
A general technique for finding maximum likelihood estimators in latent variable models is the expectation-maximization (EM) algorithm:
E-step (expectation): Use parameter estimates to update latent variable values.
M-step (maximization): Obtain new parameter estimates by maximizing the log-likelihood function based on the latent variables obtained from E-step
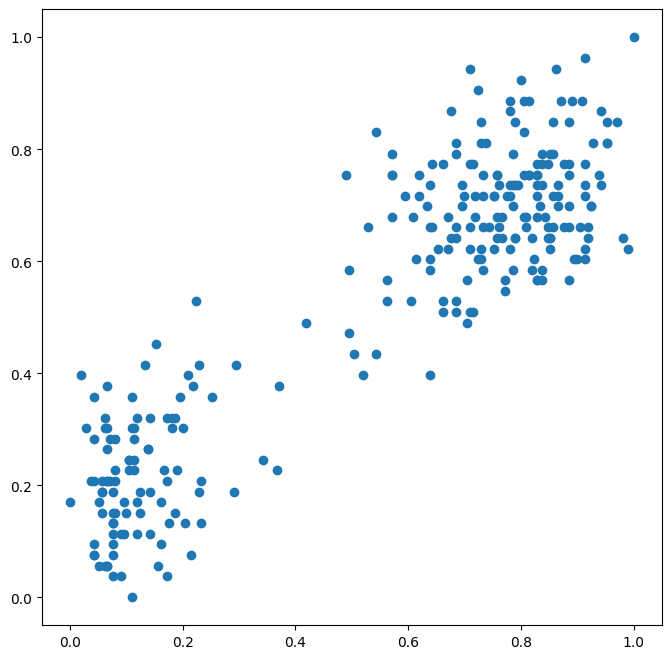
We illustrate the workings of the EM Algorithm on the Old-Faithful dataset by posing it as a 2-component gaussian mixture model.
!wget https://raw.githubusercontent.com/data-8/materials-su19/master/materials/su19/hw/hw02/old_faithful.csvimport matplotlib.pyplot as pltimport numpy as npfrom sklearn.datasets import make_blobsfrom scipy.stats import multivariate_normalimport pandas as pdfrom matplotlib import mlabfrom sklearn.preprocessing import MinMaxScalerplt.rcParams['figure.figsize'] = (8, 8)X = pd.read_csv('old_faithful.csv')[['eruptions', 'waiting']].to_numpy()X = MinMaxScaler().fit_transform(X)plt.scatter(X[:, 0], X[:, 1])# M, N = np.mgrid[min(X[:, 0]):max(X[:, 0]):0.01, min(X[:, 1]):max(X[:, 1]):0.01]M, N = np.mgrid[0:1:0.01, 0:1:0.01]grid = np.dstack((M, N))
\pi_k = Probability that a random point belongs to the kth component (also called mixing coefficients) (\sum{\pi_k} = 1)
\mu_k, Σ_k and \mathcal{N}(\mathbf{x} | \mathbf{\mu}_k, \mathbf{Σ}_k) are the parameters and pdf of the kth components respectively.
Introduction of Latent Variable
We introduce a K-dimensional latent variable \mathbf{z}; only one of the elements of \mathbf{z} will be 1 (1-of-K encoding) (also a standard basis vector).
\mathbf{z} = \mathbf{e}_k
Reformulating problem in terms of latent variable \mathbf{z}
We model the marginal distribuon over \mathbf{z} using our mixing coefficients \pi_k:
p(\mathbf{z}=\mathbf{e}_k) = \pi_k
The conditional distribution of \mathbf{x} over \mathbf{z} can be similarly modelled:
And done! We have formulated our goal using this latent variable \mathbf{z}. One more quantity of use is the conditional probablity of \mathbf{z}=\mathbf{e}_k given \mathbf{x}_i (which we will call \lambda_ik):
By the reformulation above, we have enabled the application of EM on our problem.
Let’s begin!
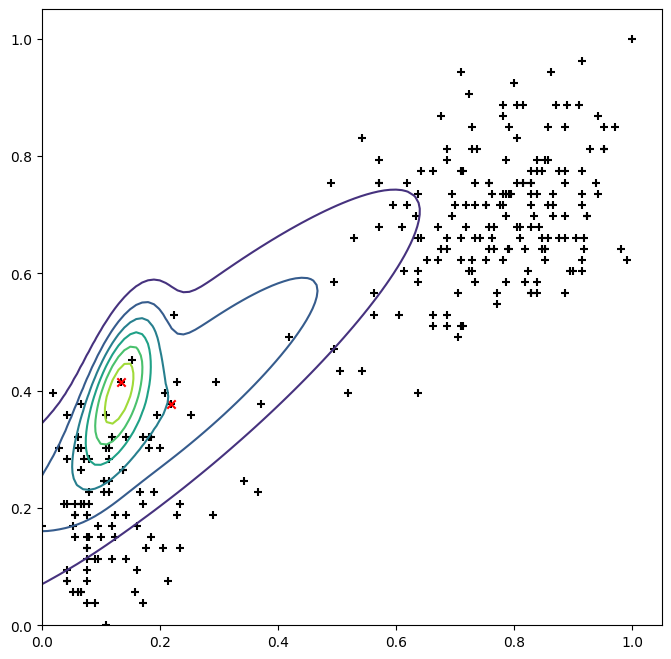
To get started, we perform the following initialization: - Pick 2 points at random as cluster centres - Hard-assign points based on proximity to centres
K =2rng = np.random.default_rng(seed=12)centres = X[rng.integers(low=0, high=len(X), size=K)]l = np.array([(lambda i: [int(i==j) for j inrange(K)])(np.argmin([np.linalg.norm(p-centre) for centre in centres])) for p in X])pi = l.sum(axis=0)/l.sum()cov = []for i inrange(K): cov.append(np.cov(X.T, ddof=0, aweights=l[:, i]))cov = np.array(cov)def plot(): plt.scatter(X[:, 0], X[:, 1], color='black', marker='+') plt.scatter(centres[:, 0], centres[:, 1], color='red', marker='x') probability_grid = np.zeros(grid.shape[:2])for i inrange(K): probability_grid += pi[i] * multivariate_normal(centres[i], cov[i]).pdf(grid) plt.contour(M, N, probability_grid) plt.show()plot()
There is a very close similarity. In fact K-Means is a restricted GMM clustering (initalize all Σ_k’s to ϵ\mathbf{I}, with ϵ → 0, and do not update in maximization step)
How does the above make it K-Means? We investigate \lambda_{ik}:
Let \phi = \arg \min f(j) = ||\mathbf{x}_i-\mathbf{\mu}_j||^2. Setting ϵ → 0, we see that in the denominator the Φ’th term goes to zero the slowest. Hence \lambda_{n\phi} → 1 while the others → 0 (note that this results in a hard-clustering).
The above is equivalent to the K-means clustering paradigm; assign clusters based on proximity from cluster centers.
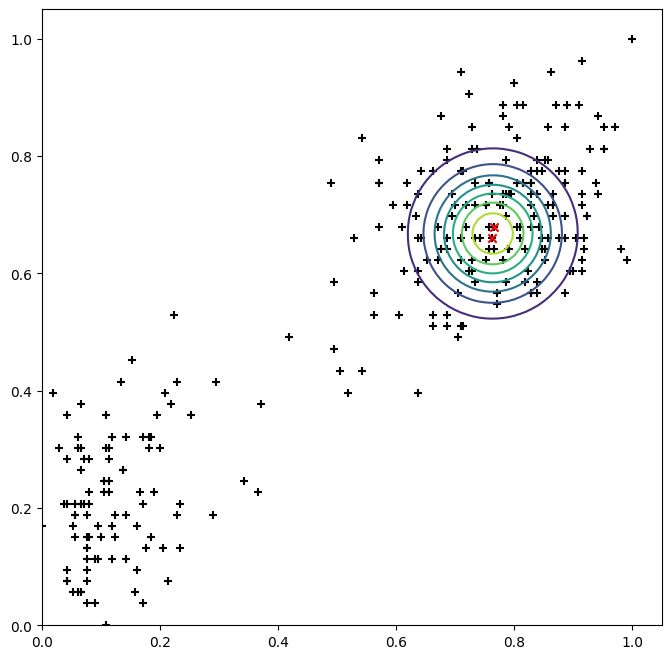
# (Restricted) Maximization Stepdef KM_Max(l): pi = l.sum(axis=0)/l.sum() centres, cov = [], []for i inrange(K): centres.append(np.dot(l[:, i], X)/l[:, i].sum()) cov.append(eps*np.eye(l.shape[1]))return pi, np.array(centres), np.array(cov)K =2eps =0.005rng = np.random.default_rng(seed=72)centres = X[rng.integers(low=0, high=len(X), size=K)]l = np.array([(lambda i: [int(i==j) for j inrange(K)])(np.argmin([np.linalg.norm(p-centre) for centre in centres])) for p in X])pi = l.sum(axis=0)/l.sum()cov = []for i inrange(K): cov.append(eps*np.eye(l.shape[1]))cov = np.array(cov)def plot(): plt.scatter(X[:, 0], X[:, 1], color='black', marker='+') plt.scatter(centres[:, 0], centres[:, 1], color='red', marker='x') probability_grid = np.zeros(grid.shape[:2])for i inrange(K): probability_grid += pi[i] * multivariate_normal(centres[i], cov[i]).pdf(grid) plt.contour(M, N, probability_grid) plt.show()plot()
a, b, c = KM_Max(l)[[round(i, 5) for i in j] for j in Exp(a, b, c)[:5]]