Slides: Click here!
Construct a checkerboard Dataset
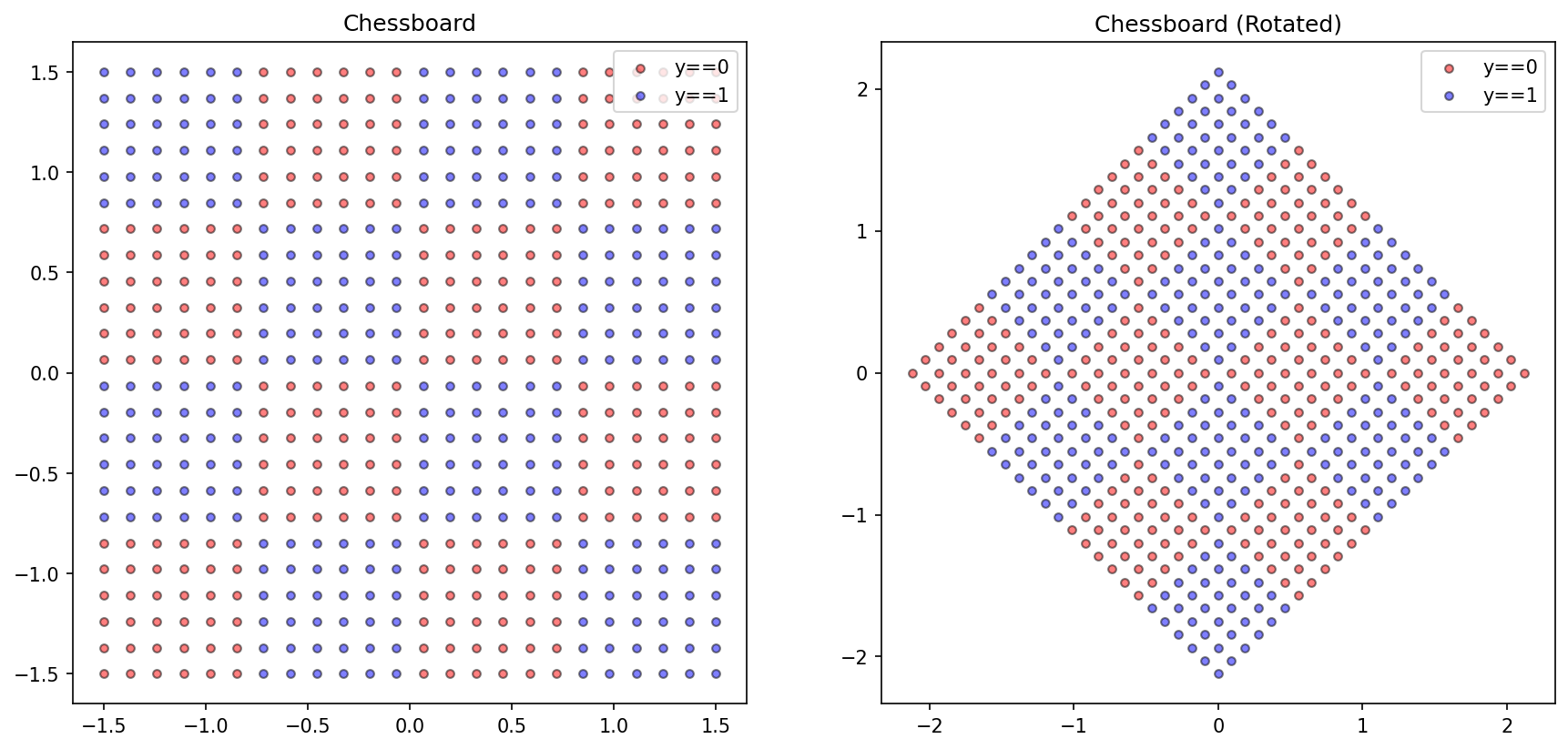
from matplotlib import pyplot as pltimport numpy as np'figure.figsize' ] = (14 , 6.3 )'figure.dpi' ] = 150 'lines.markersize' ] = 4.2 = [], []= - 1 , - 1 = 4 = 6 for i in np.linspace(0 , 3 , num= d* n):+= 1 for j in np.linspace(0 , 3 , num= d* n):+= 1 int (bool ((r// n)% 2 ) and not bool ((c// n)% 2 ) or not bool ((r// n)% 2 ) and bool ((c// n)% 2 )))= np.array(X)-= np.mean(X, axis= 0 )= np.array(y)= np.pi/ 4 = np.array([[np.cos(r), np.sin(r)], [np.sin(r), - np.cos(r)]])= X@ rotate= plt.subplots(1 , 2 )0 ][y== 0 ], X[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , alpha= 0.5 , edgecolor= 'k' )0 ][y== 1 ], X[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , alpha= 0.5 , edgecolor= 'k' )'Chessboard' )0 ][y== 0 ], X_rotated[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , alpha= 0.5 , edgecolor= 'k' )0 ][y== 1 ], X_rotated[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , alpha= 0.5 , edgecolor= 'k' )'Chessboard (Rotated)' )
Text(0.5, 1.0, 'Chessboard (Rotated)')
Decision Trees
Popular representation for interpretable classifiers; even among humans!
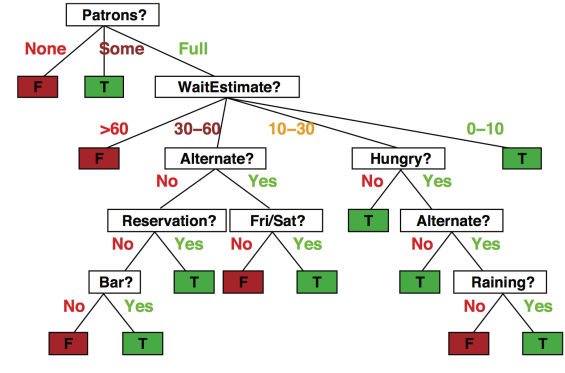
Example: I’ve just arrived at a restaurant. Should I stay (wait for a table) or go elsewhere?
One may choose to use the following set of rules to make their decision:
source: ai.berkeley.edu
Decision trees : - Have a simple Design - Interpretable - Easy to implement - Good performance in practice
Note that splits happen individually at the feature level - corresponds to splits parallel to a feature axis - Inductive bias
Inductive bias
Anything which makes the algorithm learn one pattern instead of another pattern.
Decision trees use a step-function collection for classification; but these step functions utilize one feature/variable only. Is this phenomenon sensitive to the nature of the dataset?
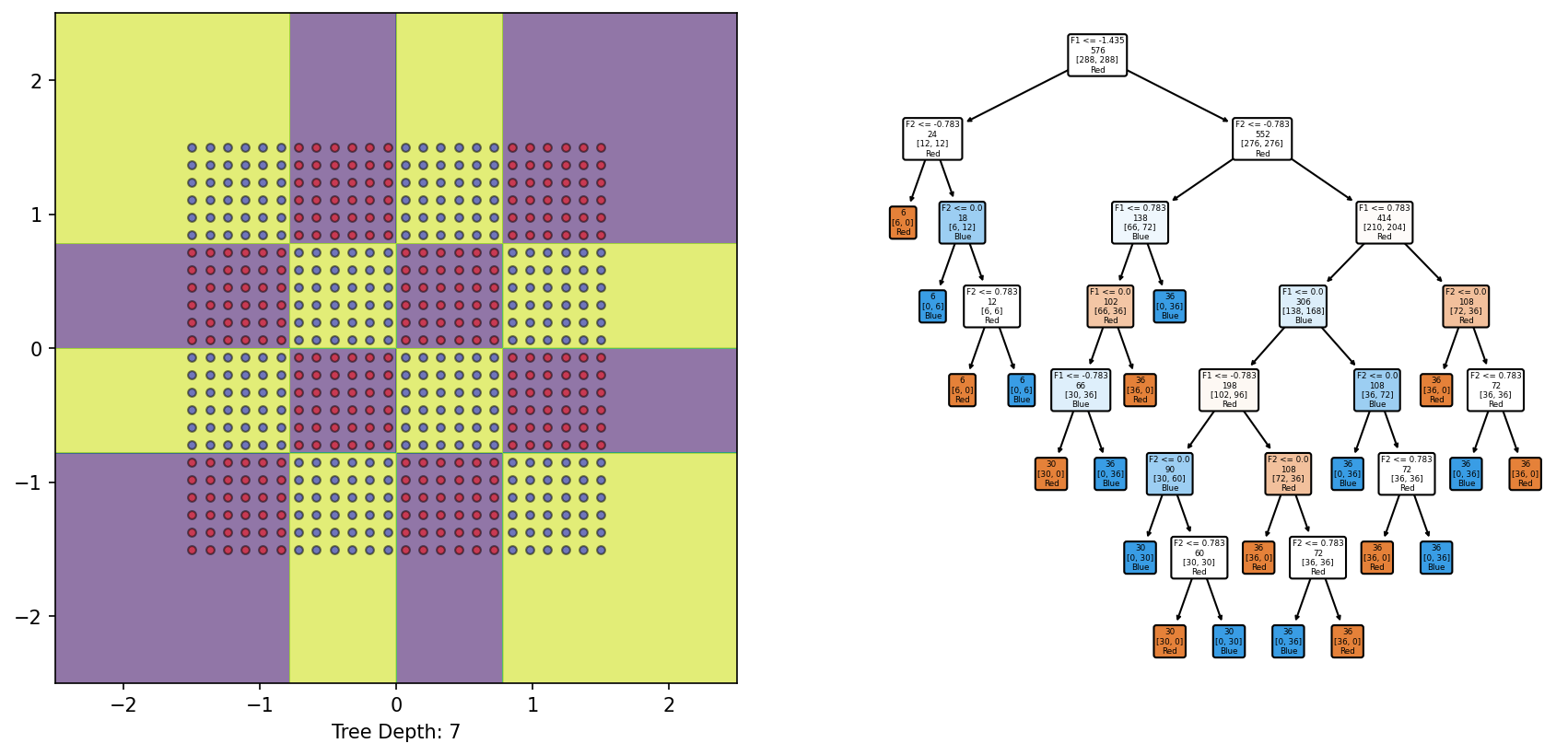
from sklearn.inspection import DecisionBoundaryDisplayfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.tree import plot_tree= DecisionTreeClassifier()= plt.subplots(1 , 2 )= DecisionBoundaryDisplay.from_estimator(DTree, X, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax = ax1)0 ][y== 0 ], X[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y== 1 ], X[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , edgecolor= 'k' , alpha= 0.5 )f'Tree Depth: { DTree. get_depth()} ' ); = 'none' , filled= True , feature_names= ['F1' , 'F2' ], class_names= ['Red' , 'Blue' ], node_ids= False , rounded= True , impurity= False , ax= ax2);
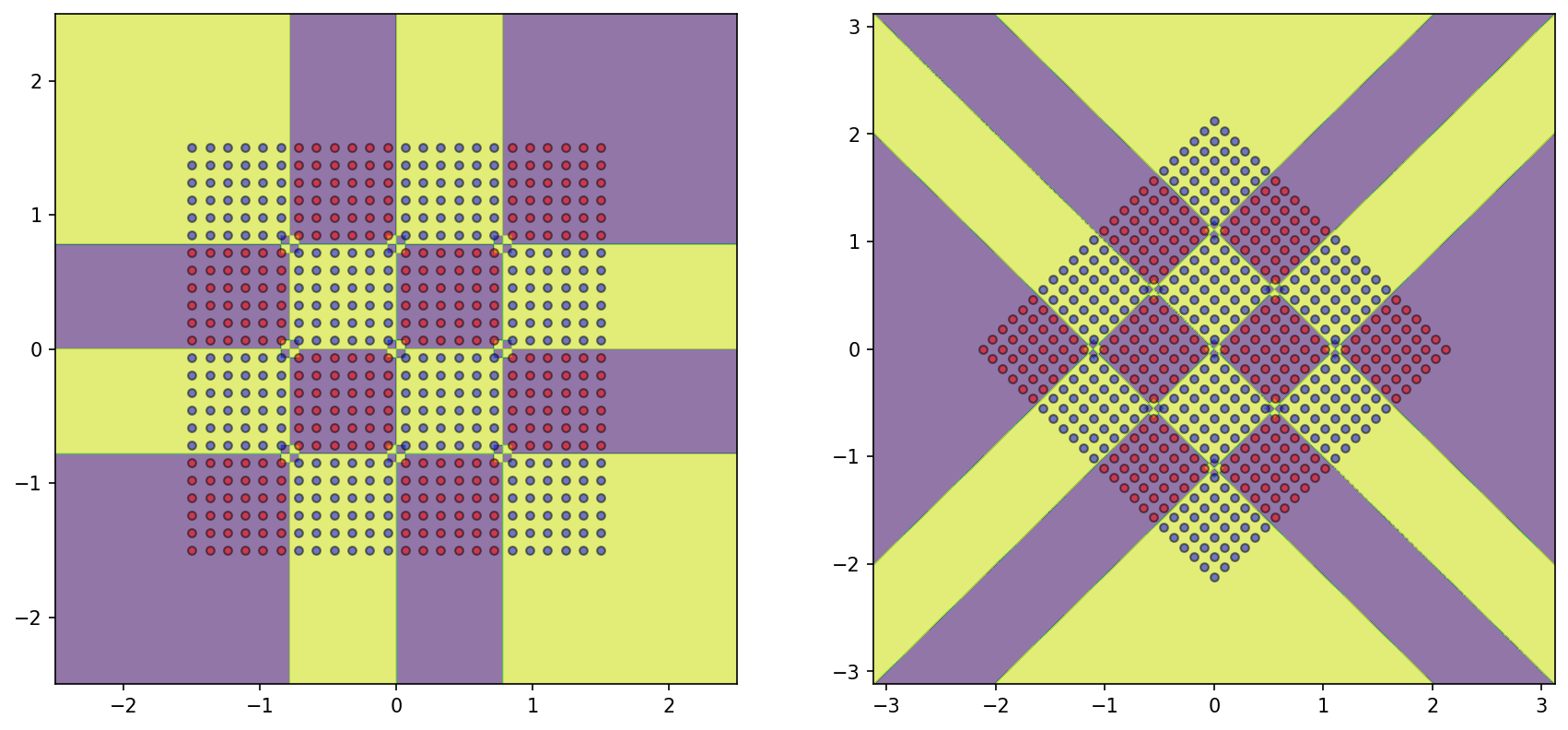
The 4x4 checkerboard dataset with alternating classes requires a tree of depth=7 to capture its structure respectively.
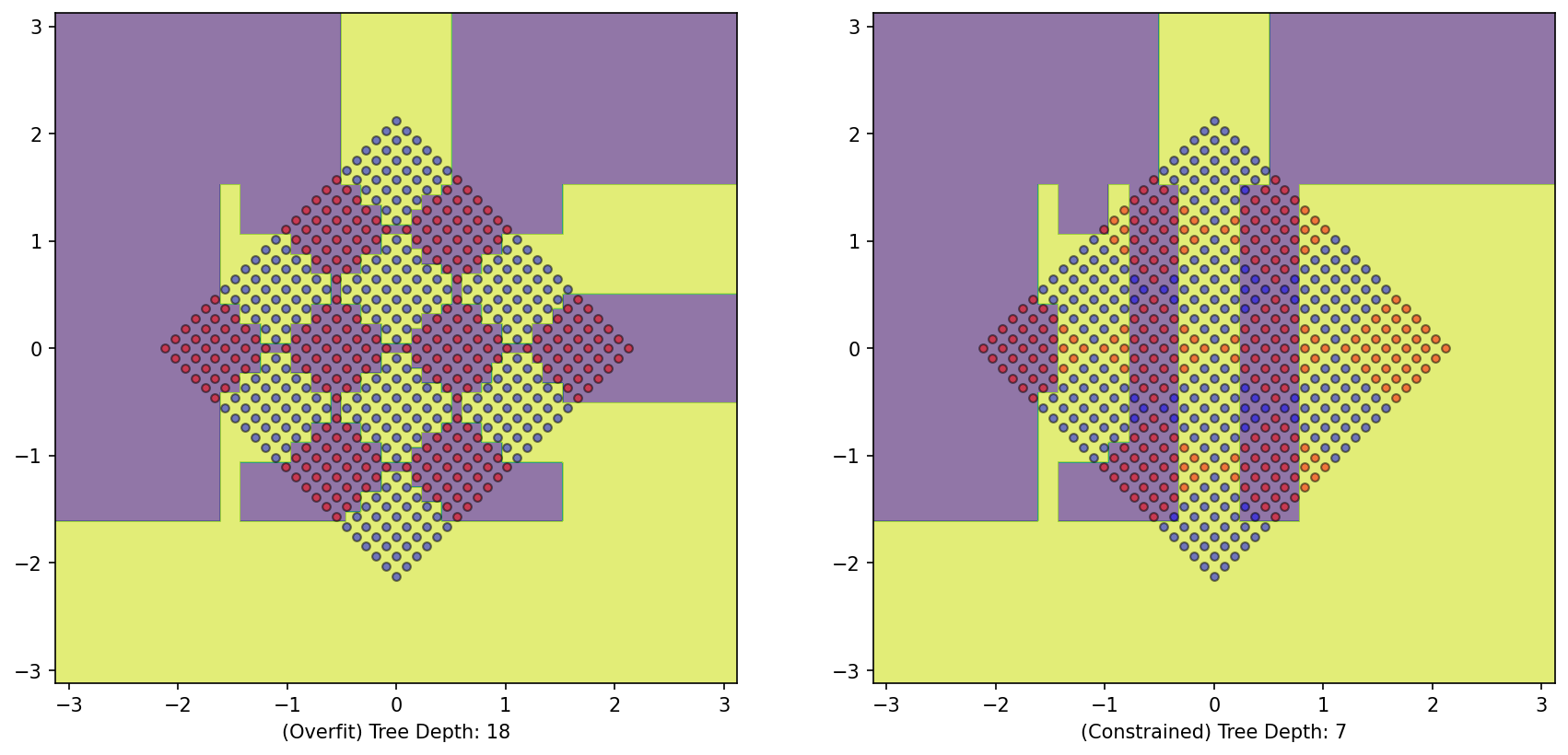
But what will happen if we try to train a tree on the rotated variant of this dataset?
= plt.subplots(1 , 2 )= DecisionTreeClassifier()= DecisionBoundaryDisplay.from_estimator(DTree_rotated, X_rotated, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax1)0 ][y== 0 ], X_rotated[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y== 1 ], X_rotated[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , edgecolor= 'k' , alpha= 0.5 )f'(Overfit) Tree Depth: { DTree_rotated. get_depth()} ' )= DecisionTreeClassifier(max_depth= 7 )= DecisionBoundaryDisplay.from_estimator(DTree_rotated_constrained, X_rotated, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax2)0 ][y== 0 ], X_rotated[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y== 1 ], X_rotated[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , edgecolor= 'k' , alpha= 0.5 )f'(Constrained) Tree Depth: { DTree_rotated_constrained. get_depth()} ' );
Oh!
The model fails to understand the generation rationale of the dataset as it suffers an inductive bias of axis-parallel splitting.
KNN
Examine the performance of KNN (with neighbors=3) on both variants of the dataset
from sklearn.neighbors import KNeighborsClassifier= plt.subplots(1 , 2 )= KNeighborsClassifier(n_neighbors= 3 )= DecisionBoundaryDisplay.from_estimator(knn, X, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax1)0 ][y== 0 ], X[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y== 1 ], X[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , edgecolor= 'k' , alpha= 0.5 )= KNeighborsClassifier(n_neighbors= 3 )= DecisionBoundaryDisplay.from_estimator(knn_rotated, X_rotated, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax2)0 ][y== 0 ], X_rotated[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y== 1 ], X_rotated[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , edgecolor= 'k' , alpha= 0.5 )
<matplotlib.collections.PathCollection at 0x79d1e140c640>
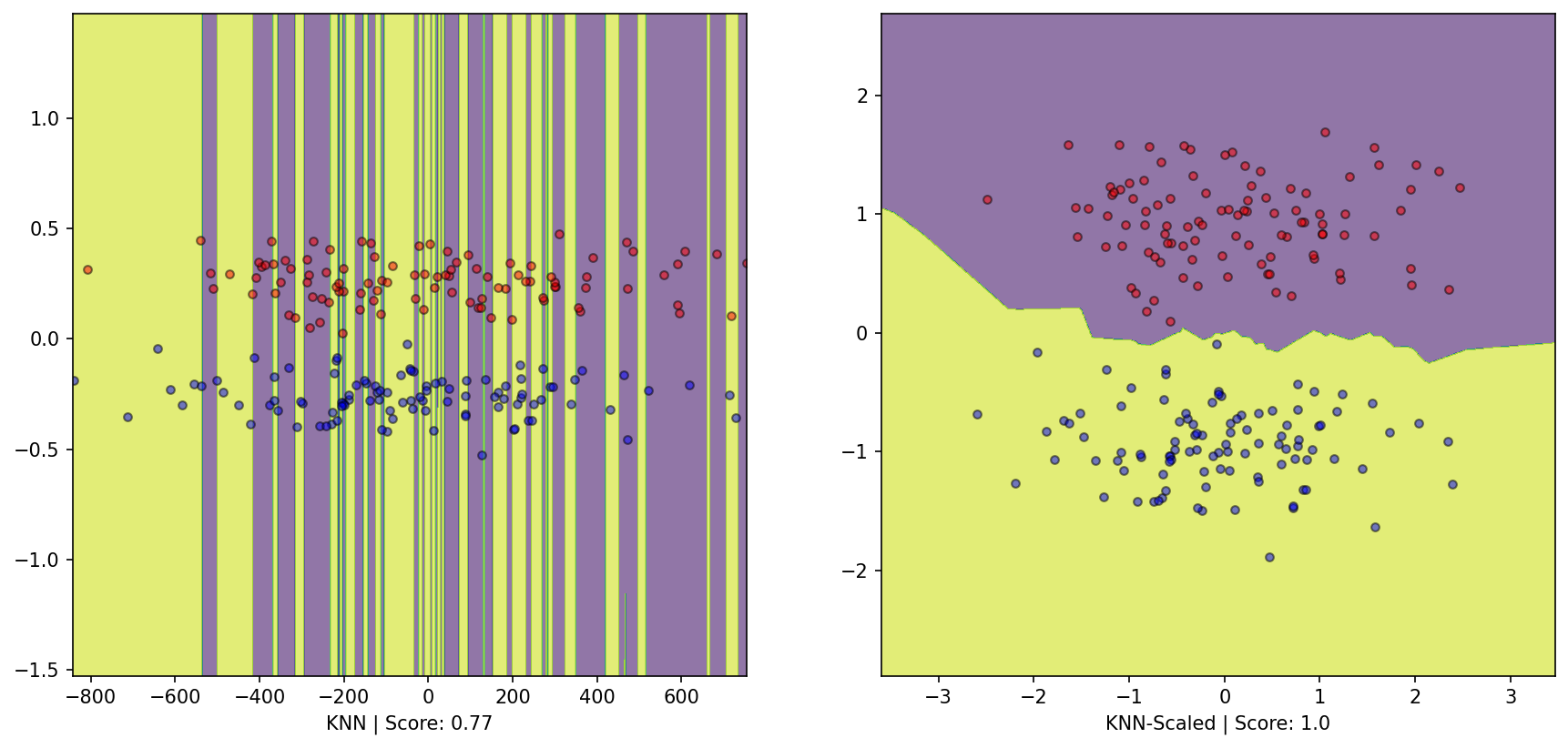
The rotation performed does not impact the performance of KNN.
What is the inductive bias in KNN then?
Inductive Bias of KNN
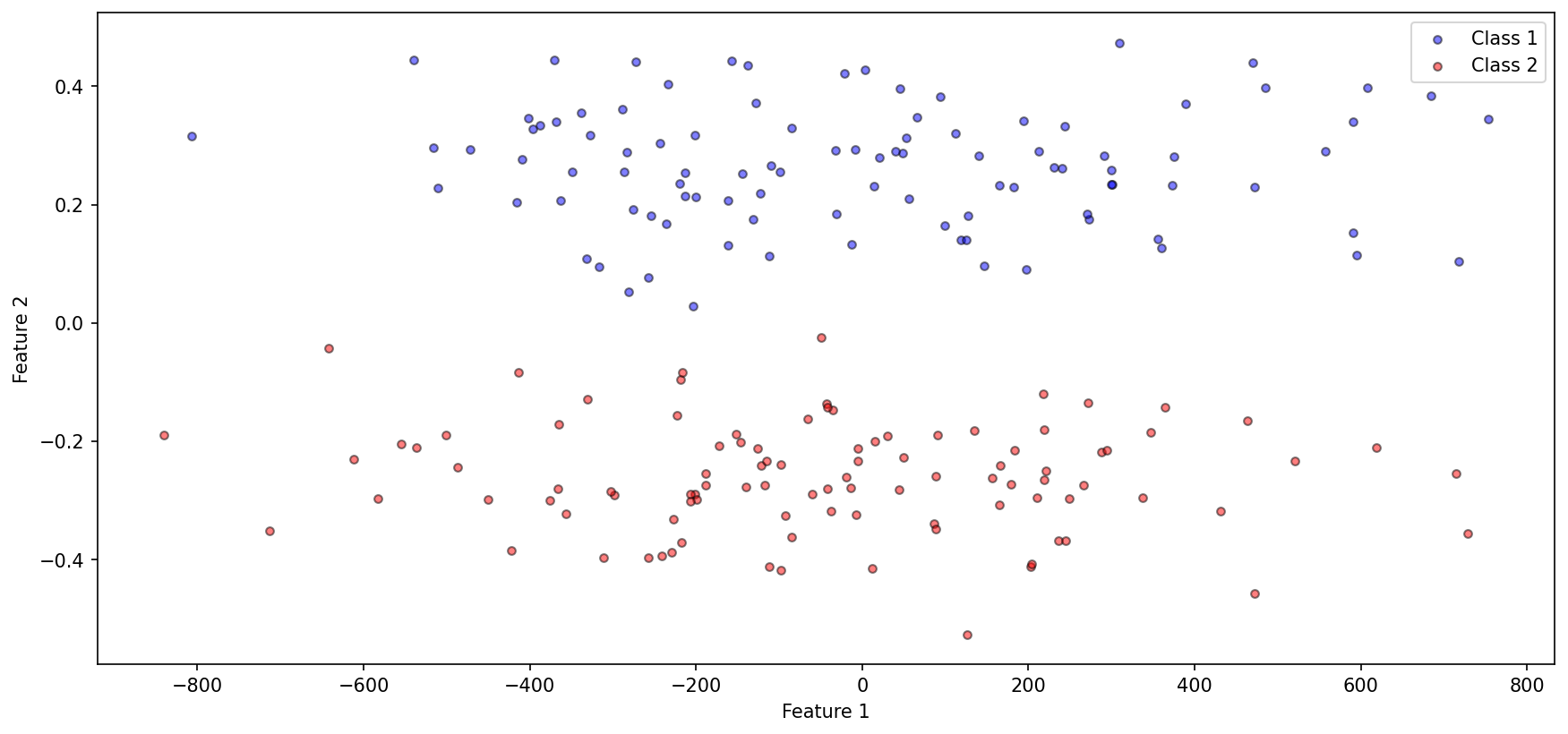
To investigate, we construct the following dataset
import numpy as npimport matplotlib.pyplot as plt'figure.figsize' ] = (14 , 6.3 )'figure.dpi' ] = 150 'lines.markersize' ] = 4.2 0 )= [0 , 0.25 ]= [[100000 , 0 ], [0 , 0.01 ]]= np.random.multivariate_normal(class1_mean, class1_cov, 100 )= [0 , - 0.25 ]= [[100000 , 0 ], [0 , 0.01 ]]= np.random.multivariate_normal(class2_mean, class2_cov, 100 )0 ], class1_data[:, 1 ], c= 'b' , label= 'Class 1' , edgecolor= 'k' , alpha= 0.5 )0 ], class2_data[:, 1 ], c= 'r' , label= 'Class 2' , edgecolor= 'k' , alpha= 0.5 )'Feature 1' )'Feature 2' )
from sklearn.preprocessing import StandardScalerfrom sklearn.model_selection import train_test_split= np.concatenate([class1_data, class2_data])= np.array([0 for _ in range (100 )] + [1 for _ in range (100 )])= StandardScaler().fit_transform(X)= y= train_test_split(X, y, test_size= 0.33 , random_state= 42 )= train_test_split(X_scaled, y, test_size= 0.33 , random_state= 42 )= KNeighborsClassifier(n_neighbors= 3 ).fit(X, y)= KNeighborsClassifier(n_neighbors= 3 ).fit(X_scaled, y)
= plt.subplots(1 , 2 )= DecisionBoundaryDisplay.from_estimator(knn, X, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax1)0 ][y== 0 ], X[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y== 1 ], X[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , edgecolor= 'k' , alpha= 0.5 )f'KNN | Score: { knn. score(X, y)} ' )= DecisionBoundaryDisplay.from_estimator(knn2, X_scaled, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax2)0 ][y_scaled== 0 ], X_scaled[:, 1 ][y_scaled== 0 ], color= 'red' , label= 'y_scaled==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y_scaled== 1 ], X_scaled[:, 1 ][y_scaled== 1 ], color= 'blue' , label= 'y_scaled==1' , edgecolor= 'k' , alpha= 0.5 )f'KNN-Scaled | Score: { knn2. score(X_scaled, y_scaled)} ' );
Oh!
We observe that scaling impacts the performance on the dataset. This reveals the inductive bias for KNN:
The algorithm assumes that entities belonging to a particular category should appear near each other, and those that are part of different groups should be distant.
Here even though the seperation is evident, the scaling makes this phenomenon invisible to the knn classifier; hence the model does not capture this structure in the dataset.
Perceptron
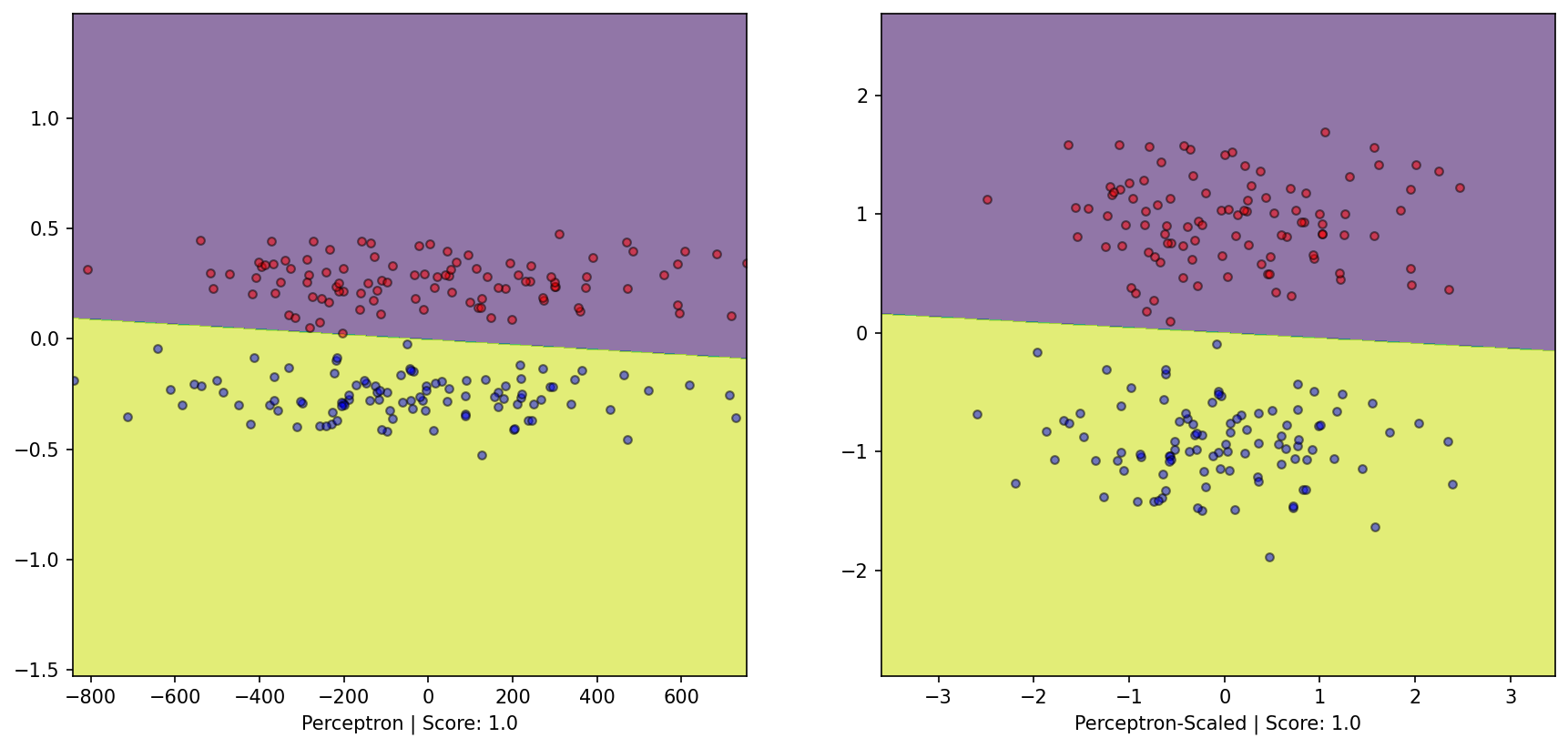
If through context we are confident that our dataset has an underlying linear seperation, we could use the Perceptron algorithm
from sklearn.linear_model import Perceptron= Perceptron(alpha= 0 , max_iter= int (1e6 ), tol= None ).fit(X, y)= Perceptron(alpha= 0 , max_iter= int (1e6 ), tol= None ).fit(X_scaled, y_scaled)= plt.subplots(1 , 2 )= DecisionBoundaryDisplay.from_estimator(perceptron, X, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax1)0 ][y== 0 ], X[:, 1 ][y== 0 ], color= 'red' , label= 'y==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y== 1 ], X[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , edgecolor= 'k' , alpha= 0.5 )f'Perceptron | Score: { perceptron. score(X, y)} ' )= DecisionBoundaryDisplay.from_estimator(perceptron_scaled, X_scaled, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax2)0 ][y_scaled== 0 ], X_scaled[:, 1 ][y_scaled== 0 ], color= 'red' , label= 'y_scaled==0' , edgecolor= 'k' , alpha= 0.5 )0 ][y_scaled== 1 ], X_scaled[:, 1 ][y_scaled== 1 ], color= 'blue' , label= 'y_scaled==1' , edgecolor= 'k' , alpha= 0.5 )f'Perceptron-Scaled | Score: { perceptron_scaled. score(X_scaled, y_scaled)} ' );
Perceptron algorithm: - Is a linear Classifier - Simple update rule: on mistake; add/subtract datapoint - Shown to converge only on linearly seperable datasets with non-zero margin (radius-margin bound) - Inductive Bias due to assumption of underlying structure of data
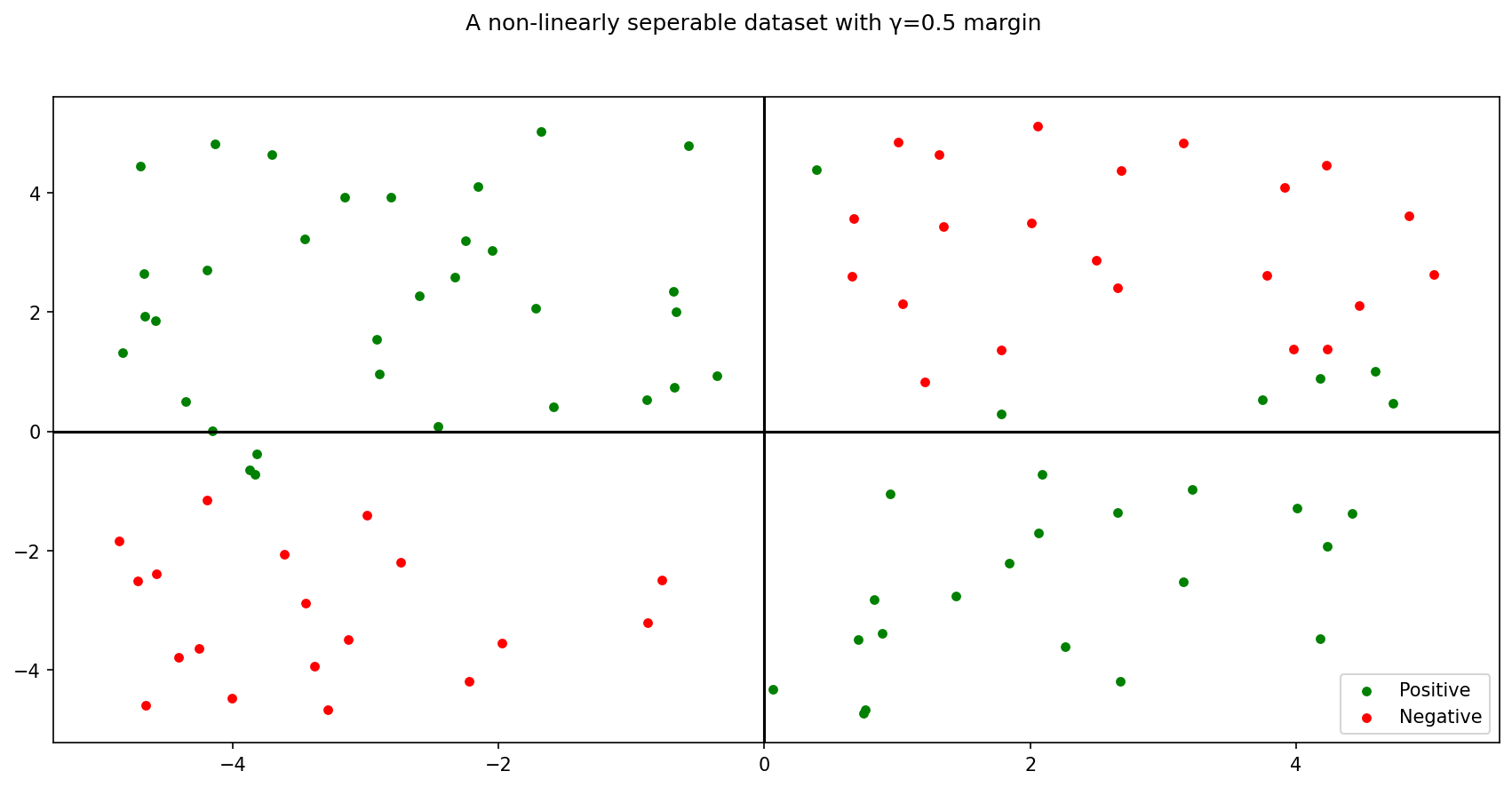
What about non-linear, say, quadratic seperability? Consider the following dataset:
1 )= np.random.rand(100 , 2 )= (X_- np.mean(X_))* 10 = [], []= lambda i: - 1 * i[0 ]/ i[1 ]= lambda i: 2 * int (i >= 0 )- 1 = lambda x: x[1 ]** 2 - 8 * x[1 ]* x[0 ]+ 2 * x[0 ]** 2 = np.array([1 , 1 ])/ np.sqrt(2 )= 0.5 for p in X_:= sep(p)if abs (d) >= gamma:= np.array(X)= np.array(y)= plt.subplots(1 , 1 )f'A non-linearly seperable dataset with γ= { gamma} margin' )0 ][y== 1 ], X[:, 1 ][y== 1 ], color= 'green' , label= 'Positive' )0 ][y!= 1 ], X[:, 1 ][y!= 1 ], color= 'red' , label= 'Negative' )= 'lower right' )= 0 , c= 'black' )= 0 , c= 'black' )
Being Mindful of the Bias
The above dataset has a seperator corresponding to a second order function of the features.
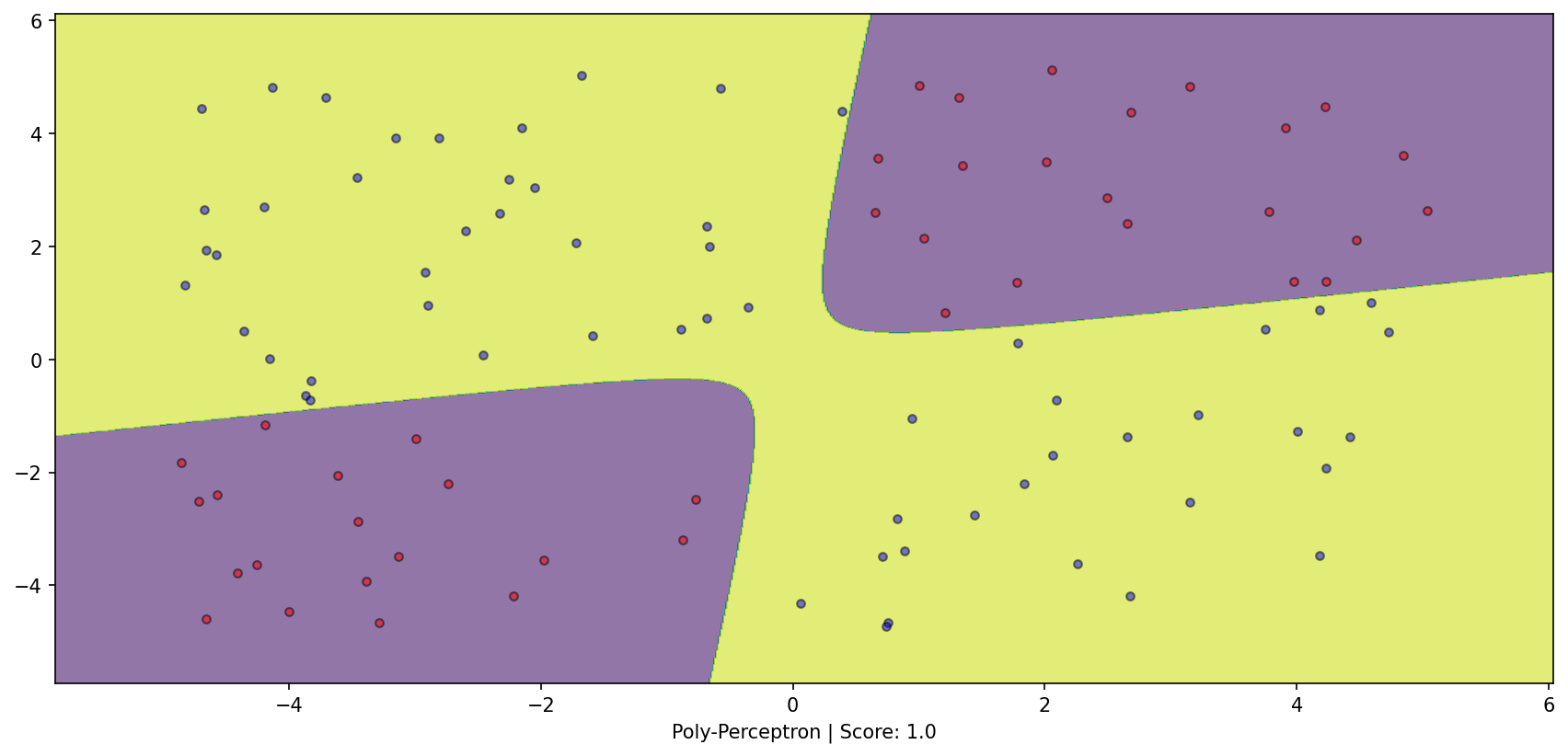
Transform the dataset and apply perceptron! Alter inductive bias to our advantage
from sklearn.pipeline import make_pipelinefrom sklearn.preprocessing import PolynomialFeaturesfrom sklearn.linear_model import Perceptron= make_pipeline(PolynomialFeatures(2 ), Perceptron(alpha= 0 , max_iter= int (1e6 ), tol= None ))= plt.subplots(1 , 1 )= DecisionBoundaryDisplay.from_estimator(poly_perceptron, X, response_method= "predict" , grid_resolution= 1000 , alpha= 0.6 , ax= ax1)0 ][y==- 1 ], X[:, 1 ][y==- 1 ], color= 'red' , label= 'y==-1' , edgecolor= 'k' , alpha= 0.5 )0 ][y== 1 ], X[:, 1 ][y== 1 ], color= 'blue' , label= 'y==1' , edgecolor= 'k' , alpha= 0.5 )f'Poly-Perceptron | Score: { poly_perceptron. score(X, y)} ' );