Exploring the Significance of ROC AUC in Classification Models
Author
Sherry Thomas
Within the realm of assessing the performance of classification models, the Receiver Operating Characteristic (ROC) curve and its corresponding Area Under the Curve (AUC) metric stand as pivotal tools. This exploration seeks to expound upon their practical significance by employing diverse datasets, offering a nuanced understanding of these fundamental concepts in model evaluation.
Understanding ROC AUC: A Brief Overview
A receiver operating characteristic curve, or ROC curve, is a graphical plot that illustrates the performance of a binary classifier model (can be used for multi class classification as well) at varying threshold values.
Did you know? The Receiver Operating Characteristic (ROC) curve originated from radar engineering during World War II. It’s named for the device that detects signals from enemy objects (the “receiver”) and its ability to distinguish between true signals and background noise (the “operating characteristic”). This curve illustrates the trade-off between true positive and false positive rates at various threshold settings. Its purpose was to assess receiver performance and optimize its settings. For more details, check out the Wikipedia article on the ROC curve or this Cross Validated question on its history.You can read more about the history of the ROC curve from this Wikipedia article or this Cross Validated question.
The ROC curve is the plot of the true positive rate (TPR) against the false positive rate (FPR) at each threshold setting.
The ROC can also be thought of as a plot of the statistical power as a function of the Type I Error of the decision rule (when the performance is calculated from just a sample of the population, it can be thought of as estimators of these quantities). The ROC curve is thus the sensitivity or recall as a function of false positive rate.
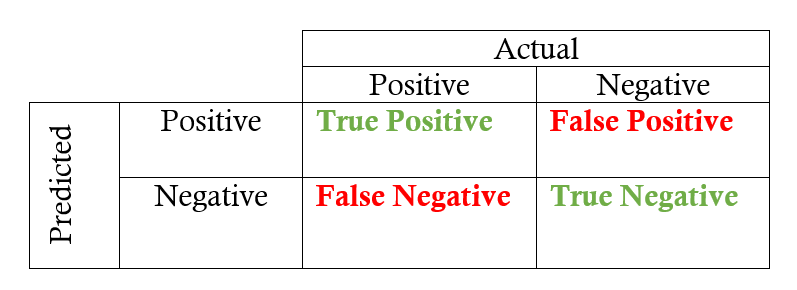
The following confusion matrix illustrates the relationship between the true positives and false positives:
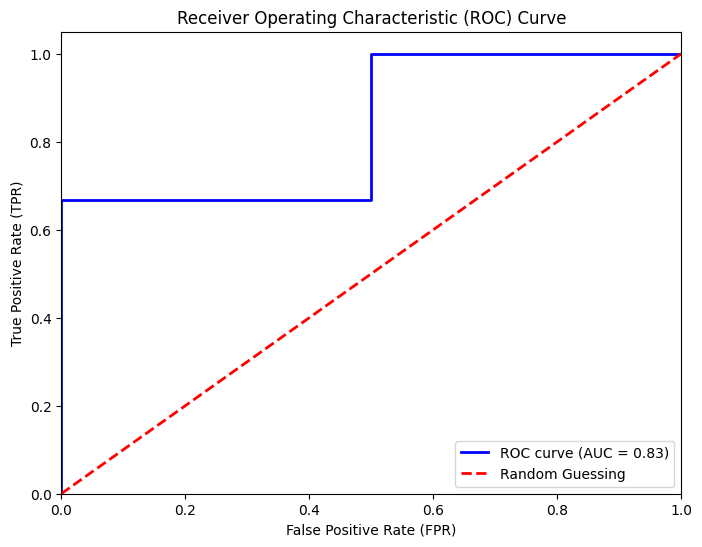
ROC Curve
The ROC curve displays how well a model separates true positives from false positives at different classification thresholds.
True Positive Rate (TPR) measures how often the model correctly identifies positives.
False Positive Rate (FPR) calculates how often the model wrongly flags negatives.
The ROC curve shows how well a model distinguishes between classes, while AUC quantifies this performance, aiding in understanding a model’s effectiveness.
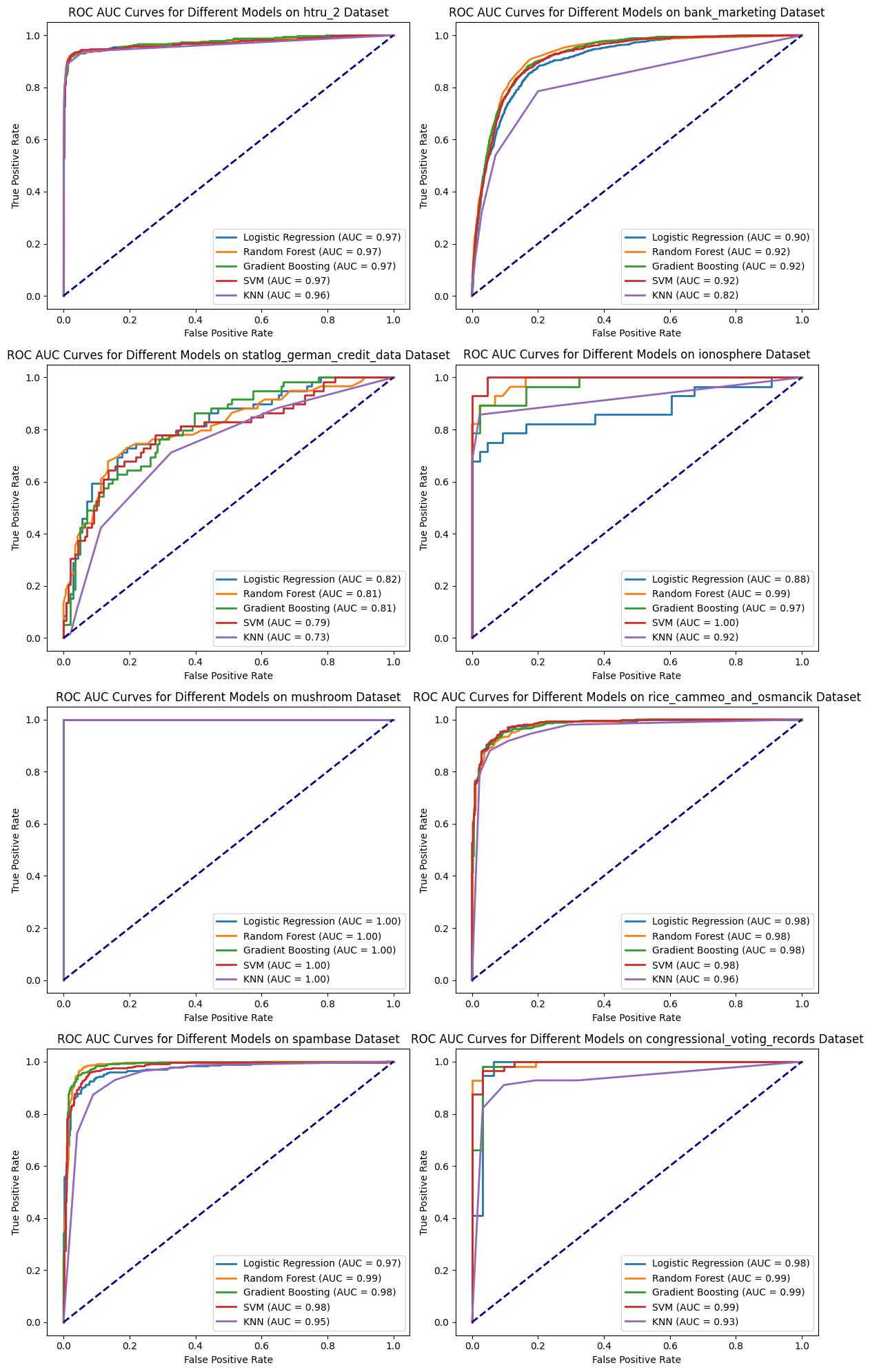
# Create subplots in a 4x2 grid (4 rows, 2 columns)fig, axs = plt.subplots(4, 2, figsize=(12, 20))axs = axs.flatten()auc_results_dict = {}for i, (dataset, dataset_name) inenumerate(datasets): auc_results_dict[dataset_name] = calculate_auc(dataset, dataset_name, axs[i])# Hide empty subplots if there are fewer than 8 datasetsfor i inrange(len(datasets), len(axs)): axs[i].axis('off')# Adjust layoutplt.tight_layout()plt.show()
# Convert the dictionary to a DataFrame for easy visualizationauc_results_df = pd.DataFrame(auc_results_dict).T# Ensure columns are of numeric data type (float)auc_results_df = auc_results_df.astype(float)# Sort columns by name (if needed)auc_results_df = auc_results_df.reindex(sorted(auc_results_df.columns), axis=1)auc_results_df
Class_Ratio 1:0
Gradient Boosting
KNN
Logistic Regression
Random Forest
SVM
htru_2
0.100806
0.973845
0.964026
0.974464
0.970874
0.971288
bank_marketing
0.132483
0.921774
0.822823
0.904550
0.924950
0.917207
statlog_german_credit_data
0.428571
0.812237
0.729475
0.817887
0.808090
0.794687
ionosphere
0.560000
0.974252
0.924834
0.875415
0.986296
0.996678
mushroom
1.074566
1.000000
1.000000
1.000000
1.000000
1.000000
rice_cammeo_and_osmancik
1.337423
0.979414
0.959702
0.981969
0.977521
0.982153
spambase
1.537783
0.984449
0.945009
0.971433
0.985448
0.978449
congressional_voting_records
1.589286
0.987327
0.931164
0.979263
0.994816
0.993088
Interpretation of AUC Values
Consistently High AUC:
Most models exhibit consistently high AUC values across various datasets.
However, relying solely on AUC for model comparison might not distinguish between models effectively due to consistently high scores.
Challenge of Class Imbalance:
Imbalanced datasets, highlighted in the ‘Class_Ratio 1:0’ column, pose challenges.
Models with high AUC might struggle to accurately predict minority classes, impacting real-world applicability.
Beyond AUC Evaluation:
Supplementary metrics like precision, recall, and F1-score, along with techniques like precision-recall curves, become crucial, particularly in imbalanced datasets.
Consideration of domain-specific knowledge guides model selection beyond AUC reliance.
Comprehensive Model Evaluation:
Emphasis on a comprehensive evaluation strategy considering class imbalance impact and multiple relevant metrics beyond AUC for informed model selection and performance assessment.
Precision, Recall, and F1-score: Complementary Metrics to ROC AUC
In addition to ROC AUC, evaluating classification models involves considering precision, recall, and the F1-score, providing nuanced insights into a model’s performance in specific scenarios.
Precision
Precision gauges the accuracy of positive predictions made by the model, measuring the ratio of true positives to the total predicted positives. Higher precision implies fewer false positives, making it crucial when minimizing false identifications is a priority.
Recall evaluates the model’s ability to correctly identify all positive instances, calculating the ratio of true positives to the actual positives. Higher recall indicates capturing a larger proportion of actual positive instances, essential in scenarios where missing positives is a greater concern.
The F1-score, a harmonic mean of precision and recall, offers a balanced assessment by considering false positives and false negatives. It becomes valuable when both precision and recall are equally important and provides a single metric summarizing their trade-offs.
When to Prioritize Precision, Recall, and F1-score over ROC AUC:
Precision: When minimizing false positives is critical, e.g., medical diagnoses where avoiding misdiagnoses is crucial.
Recall: In scenarios prioritizing capturing all positive instances, like identifying fraud in financial transactions.
F1-score: When seeking a balance between precision and recall is essential, offering a consolidated metric.
These metrics serve as complementary tools to ROC AUC, offering specific insights into different aspects of a model’s performance, allowing for informed decision-making based on specific priorities and constraints in various real-world applications.
Conclusion
In summary, the Receiver Operating Characteristic (ROC) curve and its corresponding Area Under the Curve (AUC) metric serve as pivotal elements in assessing the performance of classification models. These tools offer valuable insights into a model’s ability to distinguish between classes, aiding in informed decision-making across diverse domains.
Their significance transcends various applications, enabling stakeholders to make informed choices aligned with specific objectives and contextual needs. ROC AUC facilitates model comparison, guiding the selection of appropriate algorithms for distinct real-world scenarios. Ultimately, its practical significance lies in enhancing the understanding and evaluation of classification model performance, enabling better-informed decisions in various domains and applications.